How to reshape your data in R for analysis
Using tidyverse functions to switch between wide and long format data

One of the toughest parts of data analysis is preparing your data to be analyzed. We often have to deal with problems like NAs, typos, and data that are formatted incorrectly. In this blog post, I’m specifically going to help you with that last one — I’m going to show you how to reshape data so that it’s in the correct form for data analysis in R.

Wide vs. Long format data
Data often comes in two formats: wide or long.
Wide format data looks something like this:
This table describes the average diameter at breast height (DBH) in centimeters for three different tree species (red maple, white oak, and loblolly pine) at four sites labeled A, B, C, and D.

This is a very common way to format data, where the first column (tree species) contains unique values. Each tree species appears only once, and their DBH measurements are sorted in the table by site. So in wide format data, each row represents a tree species that we’re observing. This format is called “wide format” because the table becomes wider — if you want to add data, you need to add more columns to the table.
Long format data, in contrast, looks like this:

Here, each tree species is repeated several times in the first column, and the site names all become values in a new column, called “Site”. Now, each row contains a tree species, the site it was found at, and its DBH measurement. In long format data, each row should represent one observation (each DBH measurement = one observation). This type of data is called “long format” because the table grows longer when you add more data.
Which format is more useful?
The advantage of wide format data is that it clearly and concisely summarizes DBH measurements for us. Wide format data is what we usually use to display data as tables for presentations or papers. Long format data, by comparison, is easier to use for data analysis or visualization in R.
Long format data is also called “tidy data”, as termed by Hadley Wickham, the lead developer of the tidyverse packages. He describes “tidy data” as having the following attributes:
Each column is its own variable
Each row is one observation
Each cell is one value
Our long format data fulfills all of those requirements. Each column in our long format data represents a variable (tree species, site, and DBH). Each row represents one observation: DBH. And each cell contains one value.
Let me provide a concrete example to show why tidy data is useful. What if we go to other sites and not all the species are present there? Let’s say Quercus alba is present at Site E but not Site F, while Acer rubrum and Pinus taeda are present at Site F but not Site E. If we add this data to our wide format table, it would look like this:

There are NAs in the “Site E” column for Acer rubrum and Pinus taeda because they weren’t present at that site, so it wouldn’t make sense for them to have a DBH measurement there. Likewise, there is an NA in the “Site F” column for Quercus alba because it wasn’t present at that site. By adding data to our wide format table, we also added in missing values that we’ll have to deal with.
If we add this data to our long format table instead, we don’t have any NAs because each row in our table represents a DBH measurement. The places where there were NAs in the wide format table just don’t have a row in our long format table. Though this is an advantage in some cases, the fact that the missing observations are not there at all can also make it easy to overlook missing data in long format. The nice thing about converting from wide to long format in R, though, is that those rows with NA values can be preserved if you need them.
Long format data also clearly shows the categories that we might want to analyze the data by — we can see that we have columns for tree species and for site. This makes it easy for us to average DBH for a specific species, or summarize DBH for a specific site. Organizing data in this way makes it much easier for us to add and analyze data.

Unfortunately, data often starts in wide format and it can be tedious to manually change it to long format data. Good thing there are functions in R to help us out! Let’s see how they work.
How to reshape your data using tidyr
First, let’s upload the tidyverse package, which contains the tidyr package within it. You might need to run install.packages("tidyverse") if you don’t have this package installed yet.
library(tidyverse)
Preparing our data
Let’s also load a data set. I downloaded data describing forest area as a percent of total land area for each country of the world, from the World Bank’s Open Data catalog. You can find the same data set here to follow along.
# Load data
forest_dat <- read.csv("pct_forest_world.csv")
# Subset data and rename columns for easier visualization for this blog post
forest_dat <- forest_dat[114:122, c(1:2, 33:40)] %>%
rename(name = Country.Name, code = Country.Code)
# View data
head(forest_dat)
## name code X1988 X1989 X1990 X1991
## 114 Iraq IRQ NA NA 1.8382605 1.8414615
## 115 Iceland ISL NA NA 0.1702743 0.1830025
## 116 Israel ISR NA NA 6.0998152 6.1968577
## 117 Italy ITA NA NA 25.8058210 26.0708578
## 118 Jamaica JAM NA NA 48.1329640 48.1303786
## 119 Jordan JOR NA NA 1.1049411 1.1049411
## X1992 X1993 X1994 X1995
## 114 1.8446624 1.8478634 1.851064 1.8542653
## 115 0.1957307 0.2084589 0.221187 0.2339152
## 116 6.2939002 6.3909427 6.487985 6.5850277
## 117 26.3358947 26.6009316 26.865969 27.1310054
## 118 48.1277932 48.1252078 48.122622 48.1200369
## 119 1.1049411 1.1049411 1.104941 1.1049411
If we check out the data, we can see that the first two columns describe country name and country code. After that, each column represents one year, ranging from 1988 to 1995. There are a bunch of NAs in the data before 1990, which is likely when the data set starts.
This data is currently in wide format. Each row represents one country, and the observations (% forest area each year) are spread out across a lot of columns. As time goes on, more columns will be added for each new year. This is very common for time-series data, where each column represents a new time point.
Before we begin reshaping our data, let’s get rid of the “X” that’s in front of every single year. We can do this using the sub() function. We asked R to substitute the “X” in front of all the forest_dat column names with "" (nothing).
# Edit column names
colnames(forest_dat) <- sub("X", "", colnames(forest_dat))
# View data
head(forest_dat)
## name code 1988 1989 1990 1991 1992
## 114 Iraq IRQ NA NA 1.8382605 1.8414615 1.8446624
## 115 Iceland ISL NA NA 0.1702743 0.1830025 0.1957307
## 116 Israel ISR NA NA 6.0998152 6.1968577 6.2939002
## 117 Italy ITA NA NA 25.8058210 26.0708578 26.3358947
## 118 Jamaica JAM NA NA 48.1329640 48.1303786 48.1277932
## 119 Jordan JOR NA NA 1.1049411 1.1049411 1.1049411
## 1993 1994 1995
## 114 1.8478634 1.851064 1.8542653
## 115 0.2084589 0.221187 0.2339152
## 116 6.3909427 6.487985 6.5850277
## 117 26.6009316 26.865969 27.1310054
## 118 48.1252078 48.122622 48.1200369
## 119 1.1049411 1.104941 1.1049411
Great, now we’re ready to reshape our data.
How to use pivot_longer()
The tidyr package provides us with some useful functions to help us reshape our data. One of these functions is pivot_longer(), which — you guessed it — changes your data from wide to long format.
The important arguments to know in this function are as follows:
pivot_longer(data = data.frame, cols = columns.to.pivot, names_to = "New Column Name", values_to = "New Column Name")
data is just the data frame you want to reshape. cols lists the columns that you want to pivot. names_to is the name of the column that will be created from the variables that are in the column names. values_to is the name of the column that will be created from the values that are in the cells of the table.
This image shows how the function would pivot a simplified version of our data. You can see that each cell in the wide table on the right becomes its own row in the long table on the left:

Let’s look at a concrete example to see how the function works. In the code below, I asked the function to pivot our forest_dat data set, focusing on columns labeled “1988” through columns labeled “1995”. The function will create a new column called “year” to store all of the years that currently act as column names. The function will also create a new column to store all the % forest area values. I also added an argument, values_drop_na and set it to TRUE, which asks the function to drop rows where all values are missing (NAs).
# Create a long format table
forest_dat_long <- pivot_longer(forest_dat, cols = "1988":"1995", names_to = "year",
values_to = "pct_forest_area", values_drop_na = TRUE)
And now if you look at the data, you can see that our table is much longer than it was before (going from 9 to 54 rows). The country names are repeated several times in the first column, and now we have a column that contains the year and another column that contains the observation (% forest area). Now, each row of the data table describes one year’s measurement of % forest area in a certain country. You’ll also notice that the 1988 and 1989 columns were dropped because they contained missing values (NAs) for all countries. If we hadn’t added the values_drop_na argument, then we would still have values for 1988 and 1989 in our table, and it would just say NA for those rows.
# View data
print(forest_dat_long, n = 54)
## # A tibble: 54 × 4
## name code year pct_forest_area
## <chr> <chr> <chr> <dbl>
## 1 Iraq IRQ 1990 1.84
## 2 Iraq IRQ 1991 1.84
## 3 Iraq IRQ 1992 1.84
## 4 Iraq IRQ 1993 1.85
## 5 Iraq IRQ 1994 1.85
## 6 Iraq IRQ 1995 1.85
## 7 Iceland ISL 1990 0.170
## 8 Iceland ISL 1991 0.183
## 9 Iceland ISL 1992 0.196
## 10 Iceland ISL 1993 0.208
## 11 Iceland ISL 1994 0.221
## 12 Iceland ISL 1995 0.234
## 13 Israel ISR 1990 6.10
## 14 Israel ISR 1991 6.20
## 15 Israel ISR 1992 6.29
## 16 Israel ISR 1993 6.39
## 17 Israel ISR 1994 6.49
## 18 Israel ISR 1995 6.59
## 19 Italy ITA 1990 25.8
## 20 Italy ITA 1991 26.1
## 21 Italy ITA 1992 26.3
## 22 Italy ITA 1993 26.6
## 23 Italy ITA 1994 26.9
## 24 Italy ITA 1995 27.1
## 25 Jamaica JAM 1990 48.1
## 26 Jamaica JAM 1991 48.1
## 27 Jamaica JAM 1992 48.1
## 28 Jamaica JAM 1993 48.1
## 29 Jamaica JAM 1994 48.1
## 30 Jamaica JAM 1995 48.1
## 31 Jordan JOR 1990 1.10
## 32 Jordan JOR 1991 1.10
## 33 Jordan JOR 1992 1.10
## 34 Jordan JOR 1993 1.10
## 35 Jordan JOR 1994 1.10
## 36 Jordan JOR 1995 1.10
## 37 Japan JPN 1990 68.4
## 38 Japan JPN 1991 68.4
## 39 Japan JPN 1992 68.4
## 40 Japan JPN 1993 68.4
## 41 Japan JPN 1994 68.3
## 42 Japan JPN 1995 68.3
## 43 Kazakhstan KAZ 1990 1.27
## 44 Kazakhstan KAZ 1991 1.27
## 45 Kazakhstan KAZ 1992 1.17
## 46 Kazakhstan KAZ 1993 1.17
## 47 Kazakhstan KAZ 1994 1.17
## 48 Kazakhstan KAZ 1995 1.17
## 49 Kenya KEN 1990 6.78
## 50 Kenya KEN 1991 6.80
## 51 Kenya KEN 1992 6.82
## 52 Kenya KEN 1993 6.83
## 53 Kenya KEN 1994 6.85
## 54 Kenya KEN 1995 6.87
This format also makes it easy to plot our data. For example, let’s look at % forest cover over the years for Japan.
# Filter out all rows for Japan
japan <- filter(forest_dat_long, name == "Japan")
# Plot % forest cover over time in Japan
plot(data = japan, pct_forest_area ~ year)
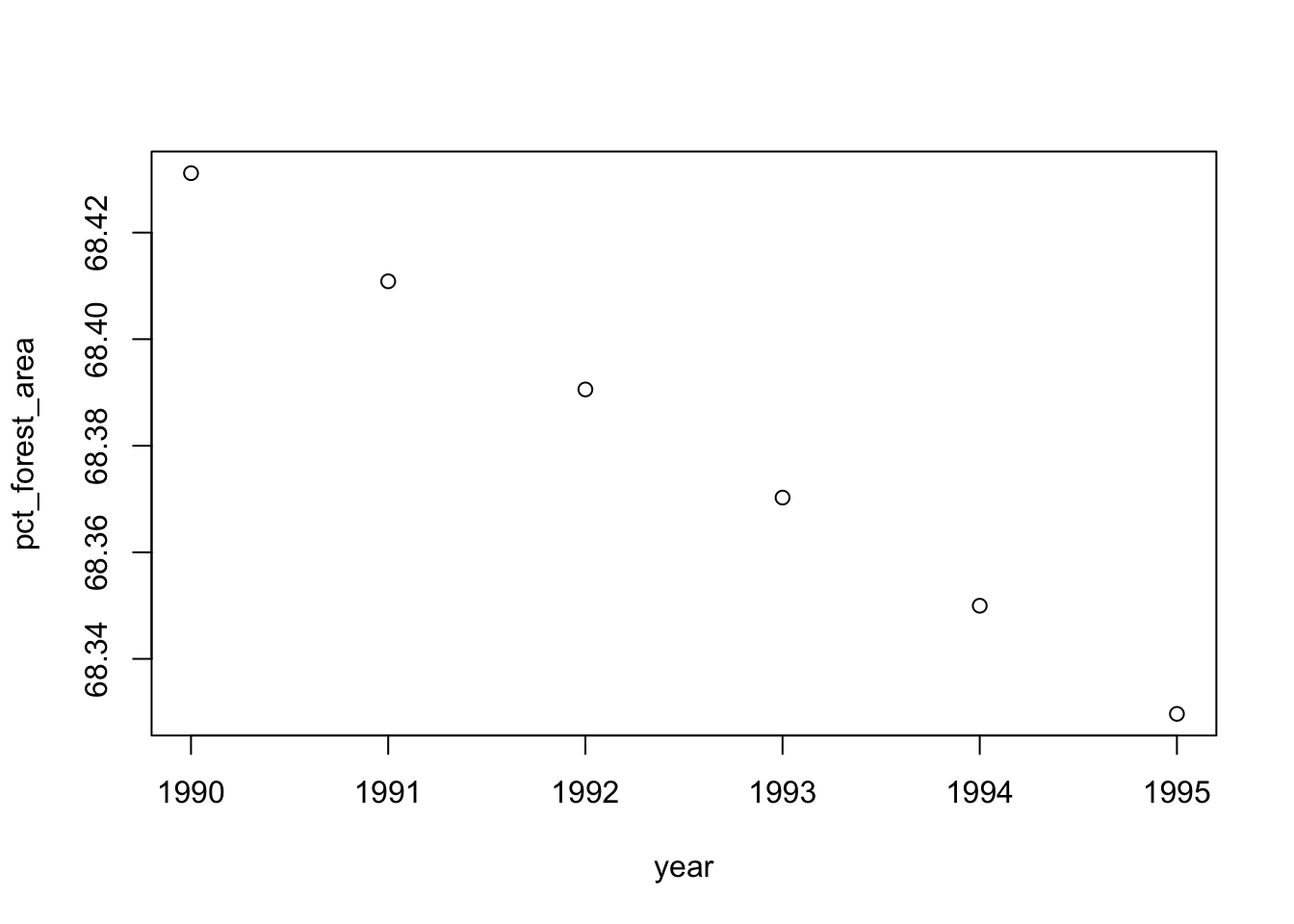
With our data in long format, we can easily see how we might want to group our data (maybe by country or by year) and then analyze it. Now let’s see how to turn our data back into a wide format table.
How to use pivot_wider()
The pivot_wider() function works similarly to the pivot_longer function, but the opposite.
Now, we want to widen our data and spread it out instead of gathering it into a longer form. The function works like this:
pivot_wider(data = data.frame, id_cols = identifying_columns, names_from = "Col with Names", values_from = "Col with Values")
data is just the data frame you want to reshape. id_cols lists the columns that contain essential identifying information for each observation. names_from is the name of the column that will be spread out to become more column names. values_from is the name of the column that the cell values will come from.
In the code below, I asked pivot_wider() to keep the columns “name” and “code” as identifying columns. I told the function to take all the new column names from the “year” column, and to take all the new values to fill in the table from the “pct_forest_area” column.
# Create a wide format table
forest_dat_wide <- pivot_wider(data = forest_dat_long, id_cols = c("name", "code"),
names_from = "year", values_from = "pct_forest_area")
# View table
print(forest_dat_wide, n = 9)
## # A tibble: 9 × 8
## name code `1990` `1991` `1992` `1993` `1994` `1995`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Iraq IRQ 1.84 1.84 1.84 1.85 1.85 1.85
## 2 Iceland ISL 0.170 0.183 0.196 0.208 0.221 0.234
## 3 Israel ISR 6.10 6.20 6.29 6.39 6.49 6.59
## 4 Italy ITA 25.8 26.1 26.3 26.6 26.9 27.1
## 5 Jamaica JAM 48.1 48.1 48.1 48.1 48.1 48.1
## 6 Jordan JOR 1.10 1.10 1.10 1.10 1.10 1.10
## 7 Japan JPN 68.4 68.4 68.4 68.4 68.3 68.3
## 8 Kazakhstan KAZ 1.27 1.27 1.17 1.17 1.17 1.17
## 9 Kenya KEN 6.78 6.80 6.82 6.83 6.85 6.87
You can see that the table looks much as it did when we first downloaded it. We have our main identifying columns for country name and code, and then we have several columns after that, each representing one year. The 1988 and 1989 columns didn’t get added back in because they only had NA values.
And now you know how to reshape your data from wide to long format and then back again. I hope this tutorial was helpful! Happy coding!
If you liked this and want learn more, you can check out the full course on the complete basics of R for ecology right here or by clicking the link below.
Also be sure to check out R-bloggers for other great tutorials on learning R